Hybrid Relation Guided Set Matching for Few-shot Action Recognition
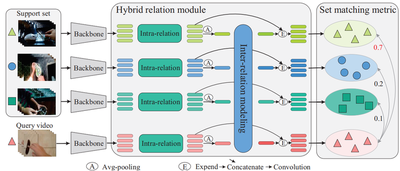
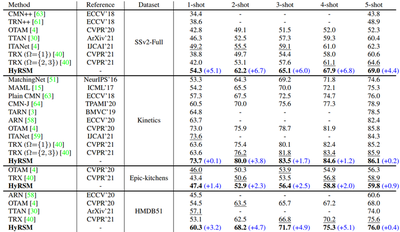
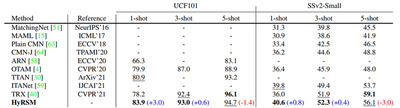
Current few-shot action recognition methods reach impressive performance by learning discriminative features for each video via episodic training and designing various temporal alignment strategies. Nevertheless, they are limited in that (a) learning individual features without considering the entire task may lose the most relevant information in the current episode, and (b) these alignment strategies may fail in misaligned instances. To overcome the two limitations, we propose a novel Hybrid Relation guided Set Matching (HyRSM) approach that incorporates two key components: hybrid relation module and set matching metric. The purpose of the hybrid relation module is to learn task-specific embeddings by fully exploiting associated relations within and cross videos in an episode. Built upon the task-specific features, we reformulate distance measure between query and support videos as a set matching problem and further design a bidirectional Mean Hausdorff Metric to improve the resilience to misaligned instances. By this means, the proposed HyRSM can be highly informative and flexible to predict query categories under the few-shot settings. We evaluate HyRSM on six challenging benchmarks, and the experimental results show its superiority over the state-of-the-art methods by a convincing margin.
Citation
@inproceedings{wang2022hyrsm,
title={Hybrid Relation Guided Set Matching for Few-shot Action Recognition},
author={Wang, Xiang and Zhang, Shiwei and Qing, Zhiwu and Tang, Mingqian and Zuo, Zhengrong and Gao, Changxin and Jin, Rong and Sang, Nong},
booktitle={{CVPR}},
year={2022}
}